DPU startup Fungible recently briefed Blocks & Files on its views regarding Intel’s Infrastructure Processing Unit. Co-founder and CEO Pradeep Sindhu said it was inadequate as a data centre cost saver, lacked imagination, and couldn’t help solve the public cloud’s trillion-dollar paradox, also known as the Hotel California problem.
Intel launched its data processing unit (DPU) line recently, differentiating itself from DPU suppliers such as Fungible and Pensando, by calling its product an Infrastructure Processing Unit (IPU). While Fungible would agree processing infrastructure-centric instructions is the key need, it thinks Intel’s DPU vision is painfully inadequate and provides much smaller TCO benefits.
The basic difference between the Intel and Fungible approaches, in Blocks & Files‘s view, is that Intel is focussed on incremental improvements using Smart NICs — such as Nvidia’s BlueField — where Fungible is looking for up to 12x improvement.
Intel says it is the DPU market leader by virtue of its sales to hyperscaler data centre operators. Such operators have thousands of servers and switches, and tens of thousands of storage drives. They sell compute cycles, so any percentage gain in compute cycle capacity is worthwhile. A ten to 20 per cent improvement — obtained by offloading network, security and storage functions to a SmartNIC — means a significant increase in server utilisation, and hence revenues.
Sindhu mentioned Amazon’s Annapurna approach, in which Amazon took infrastructure processes that were running on X86 and put them on Arm. The Arm CPUs were not as powerful as X86 processors but, at $5/core, were much lower cost than X86 which cost $40/core — an 8x improvement. By making that switch, AWS freed up X86 compute cycles, which it could sell to customers.
But Fungible wants more. Sindhu told us that he believes the infrastructure server processing burden is becoming a much bigger component of overall server CPU cycle utilisation. As application server populations in data centres increase — and as non-server processing resources such as GPUs increase as well — the amount of internal-to-the-data-centre infrastructure processing skyrockets. Sindhu said there is much more east-west data movement in such data centres than north-south data movement.
That means more and more network, storage and security processing tasks are the result of such data movement within and across the infrastructure. It is, he thinks, pointless for application servers to execute the myriad repetitive instructions needed for this work. Yes, it should be offloaded from the servers — but not in a small-scale, incremental way with SmartNICs.
In our view, that is like putting lipstick on a pig.
Sindhu said “The DPU concept is broader than Intel’s IPU concept,” but he is “happy to have Intel and Nvidia validating our vision.”
Intel lacks imagination
He said Intel’s IPU concept lacks imaginative vision because Fungible’s DPUs can do so much more than an Intel IPU. One example: legacy applications are compute-centric, so user-initiated computations should be executed close to where user data is stored. SQL primitives can be executed directly on DPUs (with SSDs plugged into them) with little data movement.
Sindhu talked about a second example: machine learning involves parameter-serving problems in which previous GPU results are put into Comma and the results distributed. “These computations are best done in the network and on-the fly,” he said. In other words, on the Fungible DPU.
“What Intel actually has is an accelerator (crypto and others), not a DPU, plus a bunch of vanilla Atom cores. Just integrating them on the same die will not solve the problem.”
DPU computations have four characteristics:
- All work arrives as packets;
- There are many, many computations multiplexed in time;
- Rate of IO (bits/sec) divided by processing instructions shows IO dominates;
- Computations are stateful, with state held in DRAM.
What is needed is a more or less complete offload of infrastructure-centric processing to dedicated processing chips, tailor-made with instructions and architecture specifically designed for IT infrastructure processing. Fungible’s view is that its specialised CPU can process these infrastructure-centric computations far more efficiently than anything else out there.
In effect, an infrastructure-focussed data processing system, using DPUs, is deployed inside a data centre as a central hub with application CPUs using GPUs to carry out processing tasks that distract from their main purpose: running application code.
Sindhu said Nvidia’s Bluefield SmartNIC is a hardware implementation of NVMe-over Fabrics’ RoCE (RDMA over Converged Ethernet) protocol, with a ConnectX 5 chip (ROCE v2) and 8 and then 16 Arm cores. “The issue” he said, “is that for RoCE it’s fine but for other computations it’s just another general purpose CPU”. In short, it’s inefficient.
“Intel and Nvidia are using 7nm designs, yet we beat the pants off them with our 16nm chip — because we have a better architecture. We’ll move to 7nm and then on to 5nm, and no-one will be able to catch us.”
“Our FS1600 does close to 15 million IOPS. If you use two Xeons with the same SSDs you’ll get one million IOPS if you’re lucky … We can see our way 20 million IOPS with software improvements.”
Fungible TCO numbers
Fungible claims that hyperscalers and near-hyperscaler data centres can realise a 12x improvement in TCO by using its specialised chips and software. That consists of 4x improvement from eliminating resource silos and then 3x from improving efficiency.
A Fungible slide shows these two aspects of Fungible’s TCO claim. The 3x efficiency improvement claim is shown by taking a nominal $100 of existing IT network, compute and storage infrastructure spend and claiming that the equivalent Fungible infrastructure spend – spend with DPU column – would be $36. That’s a 64 per cent reduction. Put another way, a $10M infrastructure spend without Fungible would be a $3.6M spend with Fungible – a saving of $6.4M.

The slide includes a middle Spend Smart NIC column, which is where Intel’s IPU-based infrastructure would fit. It partially offloads the host server CPUs but doesn’t affect the network and storage spend elements, resulting in a ten per cent TCO reduction – a $1M saving in the case of the $10M infrastructure spend example above, with Fungible saving you $5.4M more..
The rather large storage spend saving with Fungible – $40 down to $8 – is from its data reduction and erasure coding, both meaning less capacity is needed for the same number of raw terabytes.
Sindhu says overall enterprise data centre IT equipment utilisation is less than eight per cent. AWS’s data centre utilisation is 32 per cent. He says: “Fungible can bring 10x better efficiency to enterprise data centres and 2 to 2.5x better efficiency than hyperscalers.”
Fungible’s market
The Fungible marketing message is that its products let customers operate a data centre with higher efficiency than the hyperscalers themselves. That means tier-1 and tier-2 data centre operators are likely prospects for Fungible.
Equinix and other colocation centres are examples of potentially good targets for Fungible. But a lot of Equinix revenues comes from hyperscalers themselves, with systems such as direct connect brokerage. Equinix might not want to bite the hands that feed it.
Toby Owen, Fungible’s VP for Product, said: “I think a service provider (SP) would be a model for us that has a huge potential. A whole bunch of customers would rent AI/ML resources from SPs.”
Trillion-dollar paradox
Sindhu referred to the Andreessen Horowitz Trillion Dollar Paradox article by Sarah Wang and Martin Lomax:
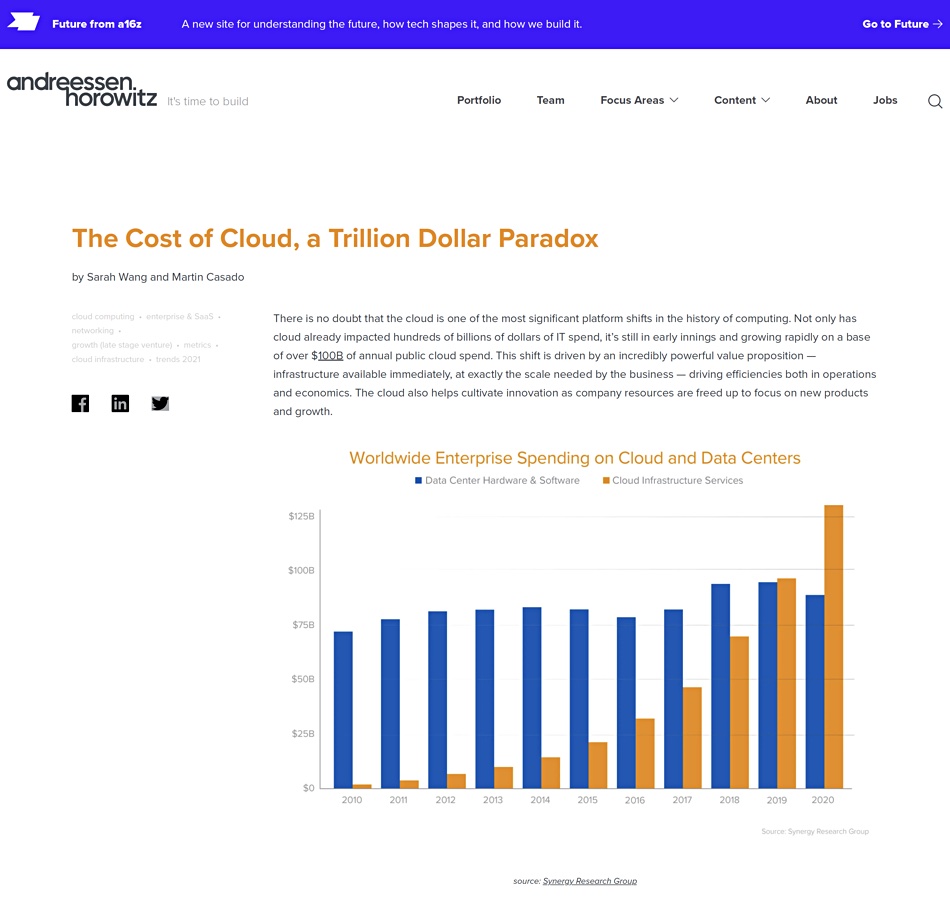
This said that cloud IT resources were cheap when companies started using them, but quite rapidly become high-cost after a few years. The chart above shows worldwide spending on on-premises data centres and the public cloud from 2010 to 2020, with the cloud growing past the on-premises spend.
Cloud spend puts so much pressure on a company’s margins that its share price falls and its market capitalisation suffers. The article explains: “It’s becoming evident that while cloud clearly delivers on its promise early on in a company’s journey, the pressure it puts on margins can start to outweigh the benefits, as a company scales and growth slows. Because this shift happens later in a company’s life, it is difficult to reverse as it’s a result of years of development focused on new features, and not infrastructure optimisation.”
Sindhu says that large public cloud customers end up in Hotel California: “You can check out any time you like, but you can never leave!“*
Wang and Casado’s conclusion is: “We show (using relatively conservative assumptions) that across 50 of the top public software companies currently utilising cloud infrastructure, an estimated $100B of market value is being lost among them due to cloud impact on margins — relative to running the infrastructure themselves.”
Sindhu’s message is that a large business can save extensive amounts of money by repatriating public cloud IT infrastructure spend to its on-premises data centres, and equipping them with Fungible’s DPU hardware and software. That way they get better than public cloud data centre efficiency and boost their market capitalisation even more.
* Hotel California lyrics © Cass County Music, Red Cloud Music, Fingers Music. Songwriters: Don Henley, Glenn Frey, Don Felder. Source: Musixmatch
"hotel" - Google News
July 19, 2021 at 04:51PM
https://ift.tt/3zhq4vs
Fungible can solve the public cloud Hotel California problem – Blocks and Files - Blocks and Files
"hotel" - Google News
https://ift.tt/3aTFdGH
https://ift.tt/2xwvOre
Bagikan Berita Ini














0 Response to "Fungible can solve the public cloud Hotel California problem – Blocks and Files - Blocks and Files"
Post a Comment